データセットとファイル
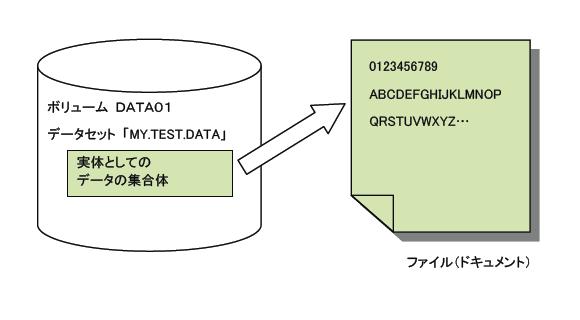
MVSでは、ファイルを「データセット」と呼びます。Windowsでは、一部のソフトウェアがファイルを「ドキュメント」と呼びます。しばしば同じ意味で使われますが、この場合のファイルとドキュメントは、データの集合をより人間の操作感覚に近いものとしてドキュメントと表現し、裏付けである記録媒体上(例えばハードディスク)での集合体をファイルとして扱う、として使い分けられたものだと考えることができます。MVSにおけるファイルとデータセットも、しばしば同じ意味で使われますが、本来は使い分けられるもので、それを理解することは重要です。
Windowsでマイドキュメントを開いてみてください。その中にはいくつかのファイルが入っているはずです。Wordファイル、Excelファイルあるいは画像のファイル何でもいいのですが、名前が付けられファイルの大きさや種類が示されていますね。MVSにおけるデータセットは、そこで表示されている1つ1つのファイルと同じです。つまり、ディスク上に記録されているデータの集合としての実体です。一方のファイルは、MVSでは実体ではなく論理的なデータの集合体として捉えたもので、プログラムで扱うデータの集合として考えることができます。z/OSの多くのマニュアルでは、データの集合体をデータセットと表現していますが、COBOLやPL/Iなどのプログラミングに関連するマニュアルでは、ファイルとデータセットの2つの言葉で解説されることが多いです。
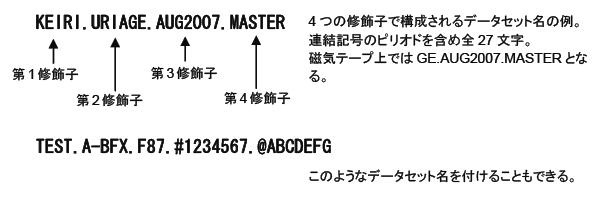
データセットに付ける名前が、データセット名です。データセット名は、1つまたは複数の修飾子(Qualify)で構成されます。修飾子は、セグメントとも呼ばれます。各々の修飾子は、1から8文字で、そのうち先頭は英字(AからZ)または国別文字(#@$または\)でなければなりません。残りの7文字は、英字、数字(0から9)、国別文字、またはハイフン(-)のいずれかです。修飾子はピリオド(.)によって連結されてデータセット名を構成します。データセット名は、すべての修飾子およびピリオドを含めて最大44文字までを使用することができます。ただし、磁気テープ上のデータセットには17文字までの名前しか付けられません。17文字以上の名前を付けた場合は、後方の17文字で認識されます。
デバイスとボリューム
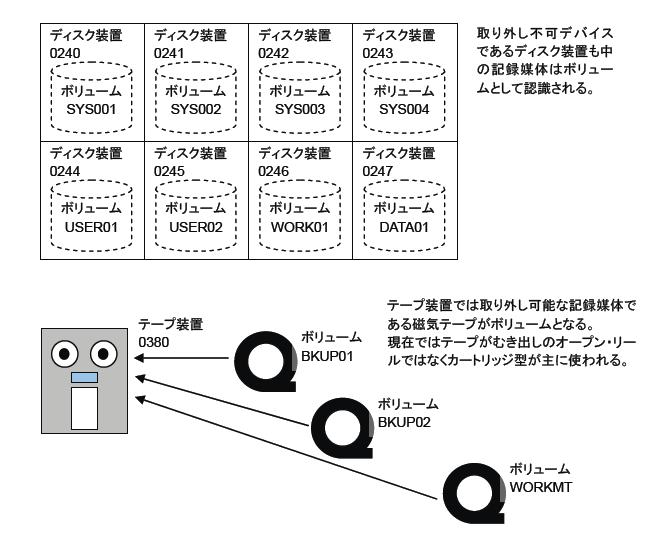
データセットは、ディスクやテープに記録され保存されます。ハードウェアとしてのディスク装置やテープ装置がデバイスです。これらのデバイスには、記録媒体(メディア)が取り付けられ、実際のデータが記録されます。MVSでは、この記録媒体をボリュームと呼びます。ボリュームとは、データセットを格納する入れ物(器)と言っていいでしょう。デバイスとボリュームは必ずしも1対1になりません。特に、テープ装置で考えるとわかりやすいです(*1)。
*1 PCのCD-ROMも同じです。CDドライブがデバイスで、記録するメディアとしてのCD-ROMがボリュームに相当します。
デバイス
MVSでは、デバイス(装置)には番号が付けられユニットとして管理されます。すべての入出力デバイスが対象になり、番号は4桁の16進数で構成されています。これを装置番号(Unit Number)と呼びます。VOS3では装置番号の代わりにニーモニック名と呼ばれる3文字の識別名が使われます。テープ装置ならT00やT01、DASDならK01やK02などのようにです。
ボリューム
テープ装置では、取り外し可能な記録媒体が使われます。リールとかカートリッジと呼ばれるものです。同じ装置に複数のテープが取り付けられる(交互にではあるが)ため、テープ上のデータセットは装置番号では正しく指し示すことができません。そこで、装置に取り付けられるテープには名前を付けて識別できるようにしています。これが、ボリューム通し番号(ボリューム名)で、最大6文字までの英数字を使用することができます。ボリュームの考え方は、ディスク装置でも同じです。ディスクは取り外し可能媒体ではありませんが、考え方として装置と記録媒体を分けていると言うことです。
ディスク、テープ共に、ボリュームには先頭にボリューム・ラベルがあり、ボリューム通し番号と所有者名などが書き込まれています。ボリューム通し番号は、個々のボリュームに付けられる識別名です。初期の頃はテープも容量が小さく、1つのデータセットが何本ものボリュームにまたがって記録されることも多かったので、通し番号の言い方がより実態を表していたのですが、ディスクに関してはボリューム名の方が表現としてわかりやすいです。そのため、正確にはボリューム通し番号(Volume Serial Number)ですが、現在ではボリューム名と呼ばれることも多いです。また、VOL=SERとも表記されます。
DASD(*2)では、ボリューム・ラベルに加え、VTOC(Volume Table Of Contents:ボリューム目録)が置かれます。VTOCには、DASD内の各データセットがどのサイズでどの位置に置かれているか、どのような形式のレコードか、DASD内の空き容量や空き位置、などの情報が格納されており、ボリュームのインデックスとして使われます。また、データセットは必ずしもDASDボリューム内の連続した場所に置かれるとは限りません。DASD内の空き状態に応じて、複数に分割されて配置される場合もあります。この場合の、データセットを構成する1つ1つの要素(連続した物理レコードの集合)をエクステントと呼びます。
*2 DASDについては「メインフレーム・コンピューターのハードウェア(ディスクとテープ)」を参照。
磁気テープ・ボリュームは、標準ラベル(SL)とラベルなし(NL)の2つの形式に分かれます。SLテープでは、先頭にボリューム・ラベルが書かれ、データセットの前後に見出しと終了のラベルが書かれ、テープ内に格納された順番にデータセットが並んでいます。ラベルにはデータセットの名前、レコード形式、ブロック長およびレコード長などが記録されています。一方のNLテープでは、一切のラベルがなく、単にデータセット内容が順番にならんでいるだけです。そのため、取り扱いがやや面倒で、テープ内のデータセットのレコード形式やブロック長、レコード長があらかじめわかっていないとデータを読み込むことができません。また、どのデータセットがテープ内で何番目に書き込まれているかもわかっていなければなりません。
マウント
記録媒体を装置に取り付けることを、MVSでは「マウント」と呼びます。デバイスはIPL時に認識されますが、ボリュームはマウントによってMVSに認識されます。ディスクのように装置と媒体が一体になっていても、マウントの手続きは必要で、いつマウントするかのタイミングの違いがあるだけです。通常、ディスクはIPL時に自動的にマウントが行われ、テープはジョブによってボリュームが要求されたときに行われます。あらかじめ装置に媒体が取り付けられていなければ、MVSはオペレーターにボリュームの取り付けをメッセージによって通知します。
カタログ
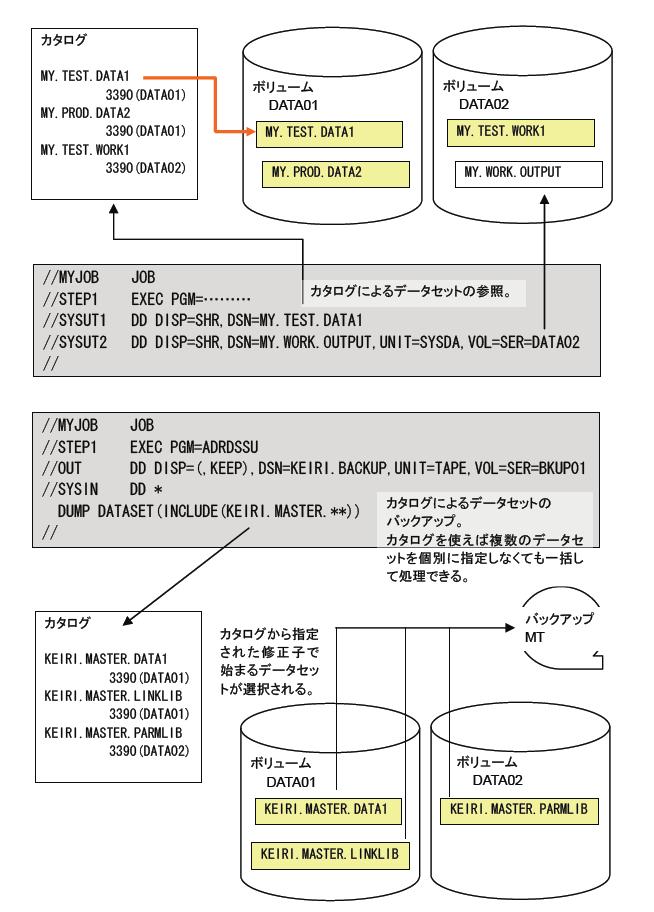
カタログは、データセット名およびそれが作成された装置の種類とボリューム名(テープであればテープ内の順序番号も含む)を記録しておく機能です。カタログされたデータセットは、DD文にデータセット名とアクセス後の後始末方法だけを指定すればアクセスできます。ユーザーは個々のデータセットが格納されているボリューム名を覚えたり、管理したりする必要がなくなります。MVSは、DD文にボリュームの指定がないと、カタログを探索してデータセットの場所を求めます。
また、カタログはデータセットを名前で管理するという面も併せ持ちます。これによってデータセットをバックアップする際などに、ボリュームを意識することなく、特定の用途にグループ化されたデータセットを一度にまとめて処理することができます。例えば、経理業務のマスターファイルが「KEIRI.MASTER.xxxxxxxx」のように命名されていれば、KEIRI.MASTERで始まるすべてのデータセットを1度の操作で容易にバックアップを行うことができます。この時、バックアップの対象になるデータセットがどのボリュームに格納されているかを意識する必要はありません。
さらに、カタログを使用する場合は、異なるボリュームであっても同じ名前のデータセットを作成することはできなくなります。そのため、同名のデータセットが散在し、どれが最新のものか、どれが正しい内容のものかが不明になる、などと言ったことも起きません。カタログ自体にセキュリティを掛ければ、規定の命名基準に合っていない名前のデータセットをむやみに作成することを防止することもできます。なお、カタログを上手に使うためには使用するデータセット名を正しく階層化することが必要です。
アロケーション
ジョブ・ステップで使用するデータセットは、あらかじめJCLのDD文によって定義されます。MVSは、ジョブ・ステップの開始時に、定義されたデータセットを探し出し、利用できるように準備します。これが、アロケーションです。アロケーションとは、プログラムが使うデータセットを、資源としてジョブ・ステップに割り当てることです。論理的なデータの集合であるファイルを、データの実体であるデータセットに関連付けることになります。
手順が多く面倒に見えますが、MVSはアロケーションの仕組みを採用することによって、プログラマーとオペレーターの負担を減らし、スループットを向上させています。
例えば、処理の結果をデータセットに出力する場合、対象のデータセットを新たに作成して書き出すのか、既存のデータセットに上書きするのか、追加するのか、同じ出力処理でも何通りもの状況が考えられます。プログラマーは、考え得るすべての状況に対応したロジックを組まねばなりません。データセットがすでに存在していたら上書きするのか最後尾に追加するかを、いずれか一方に固定した処理にするか、あるいはパラメーターなどで選択できるようにするかを考え実装しなければなりません。このようなことは、本来アプリケーションとしてのビジネス・ロジックとは直接関係しません。
また、運用する側から見ればプログラム側で機能が固定されてしまうと、プログラムに合わせた運用しかできず不便です。プログラムが常に既存のデータセットの先頭から上書きして書き出す仕様になっていれば、追加して書き出したいときには、現在のデータセットをバックアップしておき、後でマージしなければなりません。新たなデータセットに書き出したいときには、プログラムの実行前にあらかじめ空のデータセットを作成しなければなりません。このような作業が発生すれば、その分ジョブの実行に手間取り、結果としてシステムのスループットは低下します。
プログラマーが楽をすればオペレーターの負担は増しますが、柔軟な運用に対応しようとすると、プログラミングは制御的な処理で複雑になり負担も増えます。これだけのことを考えてもプログラマー、オペレーター双方に取って負担です。
MVSにおけるアロケーションは、このような問題からプログラマーとオペレーター双方の負担を減らし、柔軟な運用を可能にする仕組みなのです。
アロケーションの機能はMVSではデータ管理ではなくジョブ管理に属します。便宜上データ管理で解説しましたが、実際にはデータセットの割り当てはジョブで使用する資源として管理されるため、ジョブ管理の仕事となっています。