レコードとブロック、レコード形式
MVSでは、データセットを構成する最小の単位をレコードと呼びます。すべてのデータセットは、このレコードによって構造化されると言う特徴を持っています。また、レコードはプログラムから見たI/Oの最小単位でもあって、通常はレコード単位にファイルを読み書きします。レコードはさらにフィールドに細分化されますが、これにはMVSは一切関与しません。あくまでもプログラム側の処理によって行われます。
MVSのファイル・システムが、レコードを基本にデータを構成するのは歴史的な背景によります。コンピュータ以前のPCS(パンチカード・システム)では、紙カードを媒体にしたデータ処理を行っており、1枚のカード上のデータが処理の単位になっていました。やがてコンピュータが生まれ、さまざまな記憶装置が使われるようになり、紙の代わりにこれらの装置上にデータをカードのイメージで保存したことに始まります。
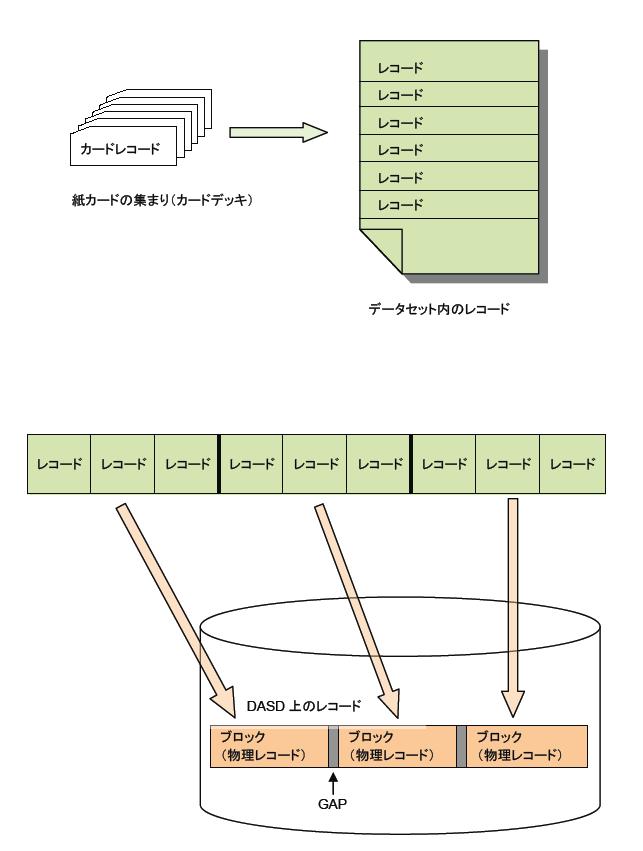
複数のレコードをまとめたものをブロックと呼びます。ブロックは、データセットがディスクやテープなどの記憶装置に記録されるときの単位であり、物理レコードとも呼ばれます。これに対して、ブロック内の各レコードは論理レコードとなります。ブロックの中にいくつのレコードが格納できるかを示す数値を、ブロック化因数(Blocking Factor)と言います。複数の論理レコードを、ブロックにまとめることをブロッキングと呼び、逆にブロックから論理レコードにばらすことをデブロッキングと呼びます。ブロッキングとデブロッキングは、通常のアクセスであればMVSによって行われます。
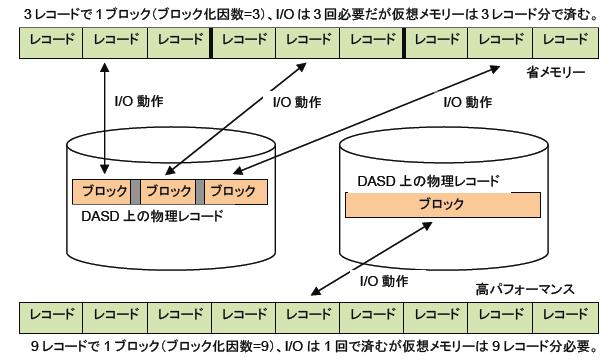
なぜレコードをブロック化するかと言うと、記憶装置のスペースを節約するためと、データの転送効率を高めるためです。ディスクでもテープでも、装置内に物理レコードを記録する時、レコードとレコードの間にギャップ(GAP)またはインターレコード・ギャップ(IRG)と呼ばれる隙間が置かれます。ギャップは、デバイス上でのレコードの区切りでもあって、ハードウェアによって自動的に書き込まれます。また、ギャップは高速で回転する磁気媒体から正確にデータを読み取るためにも必要なものです。ギャップも記録媒体上のスペースを占めるため、小さなレコードを数多く書くと、GAPの分だけ無駄なスペースが増え、実際のデータを書き込める量が少なくなってしまいます。
したがって、デバイスの使用効率を上げるためには物理レコードを可能な限り(デバイスが許す限り)長くする必要があります。また、デバイスは物理レコード単位にデータを読み書きしますので、物理レコードが長ければI/O回数を減らすことができます。I/O回数が減ればMVS側の入出力処理のオーバーヘッドも減りますから、転送効率は上がります。反面ブロック(物理レコード)が大きくなると、それだけ転送用のメモリー領域は増えることになります。初期のMVSでは、メモリーは貴重な資源でしたからやたら大きくすればよいわけではなく、処理内容と資源量のバランスを考えちょうどよい頃合いを見つける必要がありました。現在のMVSでは、実記憶もGB単位になり、仮想メモリーもふんだんに使えるので、そのような気を使う必要はなく、どちらかと言えば大きければ大きい方がよいと言う考え方に変っています。
MVSで扱うレコードにはいくつかの形式が用意されています。また、扱える長さにも取り決めがあります。レコード形式はRECFM、ブロック長はBLKSIZE、レコード長はLRECLで示されます。MVSのデータ管理機能では、レコード長、ブロック長いずれも最大32760バイトまでの長さを扱うことができます。物理レコード長の最大値は、ハードウェアであるDASDの特性に依存し、実際にはもっと長いレコードも可能です。例えば、3390型DASDであれば56664バイトです。しかし、このような長さをプログラムで直接扱うにはアセンブラー言語で直接デバイスのI/Oを行う必要があります。一般的には、32Kが最大値であると覚えていいでしょう。
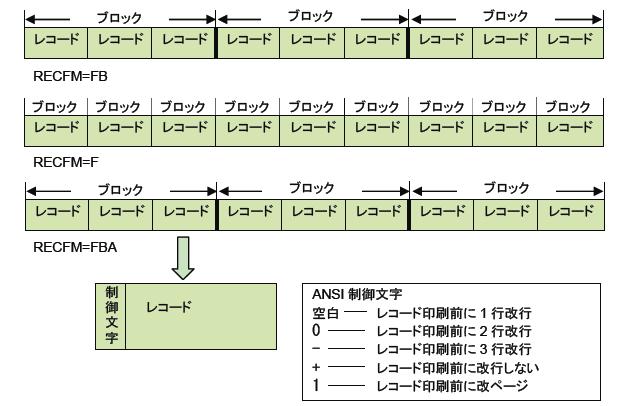
固定長レコード形式(RECFM=F[B][A|M])
すべてのレコードが同じ長さを持つレコード形式。[B]は、ブロック化されたレコードであることを示します。[A|M]は、レコードの先頭1バイトが印刷制御文字であることを示し、ANSI形式と機械形式があります。印刷制御文字は、改ページや改行時の送り行数を指定するもので、印刷用データであることをJES2ライターに示すために使われます。[A|M]がなくても印刷用データとして使用できますが、きめ細かな改行制御はできません。
固定長レコードは、MVSでは最も多く使われるレコード形式です。単純で取り扱いも容易ですし、プログラムも単純にできます。短所は、スペース効率が悪い点です。特に、印刷データの場合は、すべての行が同じ長さであることは少なく、印刷文字列が短ければ、レコードの後ろは空白で埋められることが多いです。この場合でも空白は文字としてディスク・スペースを占めてしまいます。しかしながら、非常にわかりやすいので最もよく使われるレコード形式です。
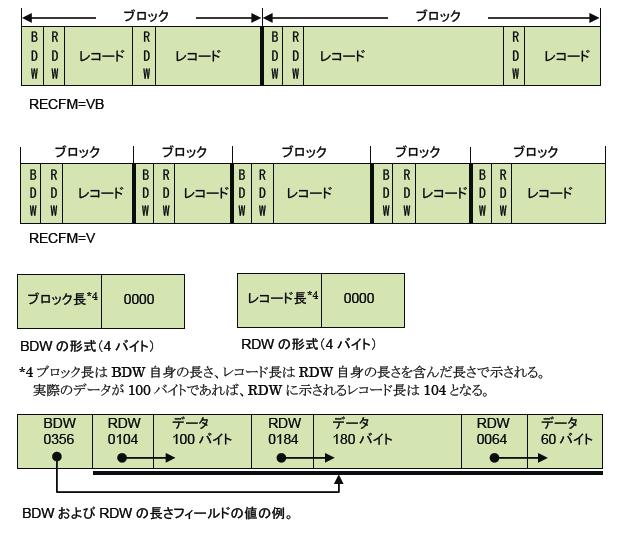
可変長レコード形式(RECFM=V[B][A|M])
レコードの先頭にそのレコードの長さを示すフィールド(RDW:Record Descriptor Word)を持つレコード形式です。レコードによって、実際のデータとしての長さが異なるので可変長と呼ばれます。[B][A|M]に関しては、固定長レコード形式と意味は同じです。ブロック化されたレコードでは、ブロックの先頭にはブロック自身の長さを示すフィールド(BDW:Block Descriptor Word)が付加されます。そのため最小レコード長とブロック長は、これらRDWとBDWの長さ4バイトずつを加えた長さである必要があります。スペース効率重視の形式ですが、極端に短いレコードは可変長形式にすると逆にスペース効率が悪くなります。例えデータが1バイトであっても、RDWが加わり計5バイトとなってしまうからです。また各レコードの長さはアクセスして見なければわからないので、プログラムはレコード内のフィールドを単純にマッピングできず、処理は固定長形式に比べ複雑になります。しかしながら、印刷データの場合は、印刷文字列の長さに応じてレコードを作成でき、長さを合わせるための空白文字の埋め込みなどが不要です。
不定長レコード形式(RECFM=U)
長さが一定ではないが、可変長レコードのようにレコード上に長さを示すフィールドを持たないレコード形式です。長さは、書き出し時にプログラムがMVSにパラメーターで渡しますが、読み込み時はデバイスから転送された長さでMVSから通知されます。U形式も読んでみなければ長さはわからないと言う特徴を持ち、ブロック単位でのみアクセスできます。主に、ロードモジュール・ライブラリーに使用され、一般のユーザープログラムで使われることはほとんどありません。
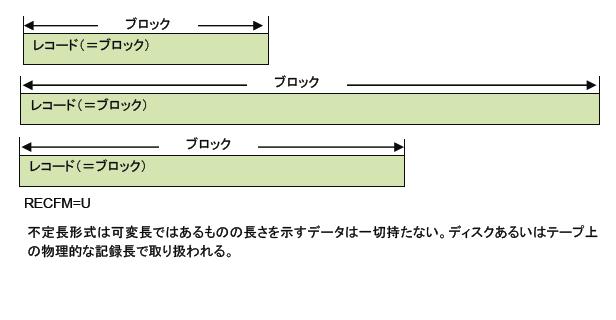
データセットの種類とアクセス方式
MVSのデータセットには、レコードの配列方法によって複数の種類があり、編成(DSORG:Dataset Organization)と呼ばれます。アクセス方式(AM:Access Method:アクセス・メソッド)は、プログラムでデータセットの読み書きを行うための、MVSのプログラミング・インタフェースで、データセット編成に応じたアクセス方式がデータ管理によって提供されています。これは、アセンブラー言語で使用するためのプログラミング・インタフェースで、COBOLやPL/Iでは、ファイル定義やファイルアクセス・ステートメントを介して間接的に使用されます。どのような言語でプログラムを作成するにせよ、あるいはプログラム作成には直接携わらないにせよ、データセット編成とアクセス方式(の概要)を理解することは、MVSでデータセットを作成し、編集し、操作する上で必要かつ重要です。複数のデータセット編成がありますが、現在でもよく使われる代表的なものに限定して紹介します。
アクセス方式は、OSのデータ管理に属する機能です。MVSでデータ管理の機能を提供するのが「DFP」(Data Facility Product )と呼ばれるコンポーネントでした。現在では、DFSMSdfpとしてDFSMSに統合されています。MSPとVOS3では「データ管理」です。
- OPEN … データセットをオープンする。
- OPEN … データセットをオープンする。
- GET … 次のレコードを読み込む。
- PUT … 次のレコードとして書き込む。
- PUTX … 直前に読み込んだレコードを更新する。
- CLOSE … データセットをクローズする。
- ディレクトリーには索引とキャッシュが付き、PDSより高速なディレクトリー・エントリーの探索ができる。
- ディレクトリー部は必要に応じて自動的に拡張される。
- 圧縮の必要がない(必要に応じて内部で自動的に行われる)。
- メンバー名は8バイトだが、別名として1024バイトまでの長い名前を付けることができる。
- 複数のジョブで同時にメンバーを登録・更新できる。
- メンバーは格納時には最適なサイズでブロック化されるが、読み出し時にはプログラムが指定するブロックサイズで渡るように調整される。
- 1つのアクセス方式(VSAM)で目的に応じた複数の編成を持つファイルをサポートする。
- デバイスの物理的特性を意識する必要がない(従来は装置の特性や、装置上の物理的な記録フォーマットを意識する必要があった。特に基本アクセス方式)。
- アクセス効率の向上。
- カタログによるデータセット管理(データセットの構成情報はVTOCだけでなく、カタログも使用するためデータセットの構造がVTOCの仕様に制限されない)。
- データの機密保護や保全性の向上。
- KSDS(キー順データセット)
- ESDS(エントリー順データセット)
- RRDS(相対レコードデータセット)
- LDS(リニアデータセット)
順次データセットとQSAM・BSAM
順次データセットは、レコードが先頭から順番に並んでいるデータセットで、MVSにおける最も基本的なデータセットです。ディスク、テープ、プリンターなど、どのような装置にも記録・出力できるので、さまざまなデータの保管や印刷(出力)用に使われます。順データセット(MSP)、順編成データセット(VOS3)、PS(Physically Sequential)ファイル、SAMファイルなどいくつかの呼び名があります。SAMは、Sequential Access Methodの略で、順次データセットのアクセス方式では、QSAM(Queued SAM)とBSAM(Basic SAM)の2種類があります。
BSAMは、基本的なアクセス方式でデータセットをブロック単位でアクセスします。論理レコードへの分割はアプリケーション・プログラム自らが行う必要があり少々面倒ですが、ブロックを飛ばしてアクセスしたり、後ろへ戻ったりなど細かな制御ができます。反面I/Oを効率よく行うためのバッファリング制御なども自分でやらなければならないので、機能や性能を求めるとプログラムは複雑になります。使いこなすためには、ハードウェア上にデータがどのように記録されるかの知識も必要です。
QSAMは、データセットをレコード(論理レコード)単位にアクセスするためのインタフェースです。特長は、レコード単位であるためプログラミングが容易であること、自動的なバッファリング制御により、高速なI/O処理が行われることです。BSAMに比べきめ細かな制御機能は省かれていますが、それらは一般のデータセットのアクセスではほとんど必要とされません。
QSAMでは主に以下のI/O機能が提供されます。
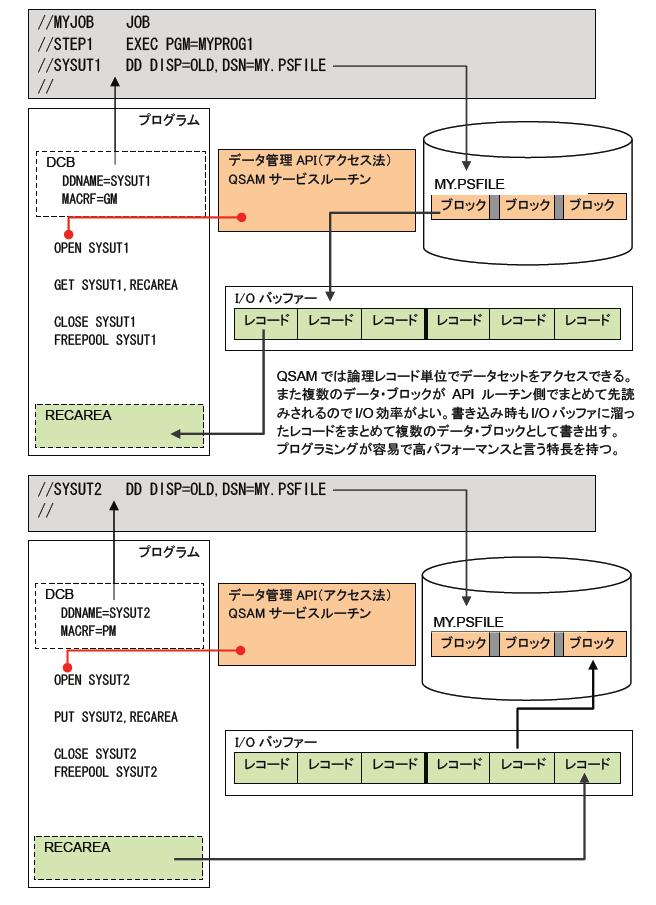
区分データセットとBPAM
区分データセットは、複数の順次ファイルを1つのデータセットにまとめて格納できるようにしたものです。データセット内の1つ1つの順次ファイルをメンバーと呼びます。データセットは、ディレクトリー部とメンバー部の2つに分かれて構成され、ディレクトリー部はデータセットの先頭にあります。ディレクトリー部は1つまたは複数のディレクトリー・ブロックで構成され、どのメンバーがどの位置にあるかなどを管理するインデックスとしての役割を持ちます。区分データセットは、構造上の特性からDASDボリュームにのみ作成することができますが、複数ボリュームにまたがることはできません。
区分データセットは、主にプログラムやJCL、パラメーターなどのライブラリーファイルとして使われます。また、プログラムでも実行可能形式のロードモジュールは、必ずこの区分データセットに格納されなければなりません。このデータセットも、区分編成データセット(VOS3)、PO(Partitioned Organization)ファイル、PDS(Partitioned Dataset)ファイルまたは単にPDSなど、やはりいくつかの呼び名があります。
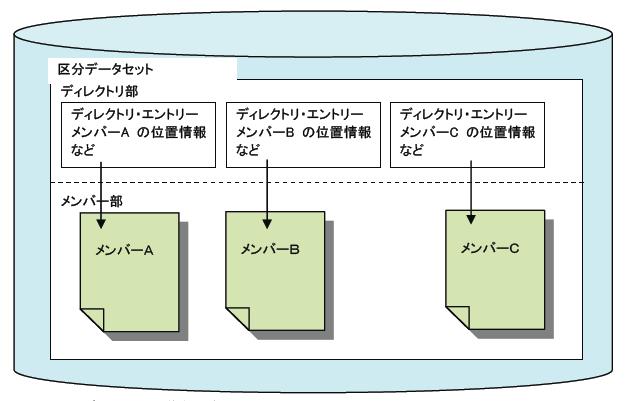
区分データセットの大きな特性が、圧縮処理が必要であることです。区分データセットでは、新しくメンバーを作る時も更新時も、メンバーは必ずメンバー部の最後尾に追加する形で書き込まれます。同じメンバーの再書き込みで、レコード数が増えていなくても元の位置に書き戻されることはありません。新規、既存の区別なく、必ずメンバー部の最後尾に追加され、メンバー領域のフラグメンテーションが避けられない仕様になっています。このため、メンバーの読み出しと書き込みを繰り返して行くと、やがてメンバー部に空きスペースがなくなり、メンバーの追加や更新ができなくなります。メンバーの追加のみでこうなったのであれば、データセット自体の大きさが足りないので作り直しですが、更新の繰り返しでこうなったのであれば、更新前のメンバーが使用していたスペースは空きのままで残っていますから、各メンバーの格納位置をずらすことで解消できます。これが区分データセットの圧縮で、バッチまたは対話処理のユーティリティで行うことができます。
PAMは、Partitioned Access Methodの略で区分データセットのアクセス方式で、BPAM(Basic PAM)の1種類しかありません。ただし、メンバーはそれ自体が1つの順次データセットなので、メンバーのレコードのみにアクセスするならば、QSAMでアクセスすることが可能です。その際は、DD文でDSN=dsname(member)の形式で直接メンバーを指定してアロケーションします。BPAMは、BSAMにディレクトリー部の制御機能を加えたもので、メンバー自体のアクセスはBSAMとほぼ同じです。よって、BPAMでもメンバーはブロック単位でしかアクセスできません。
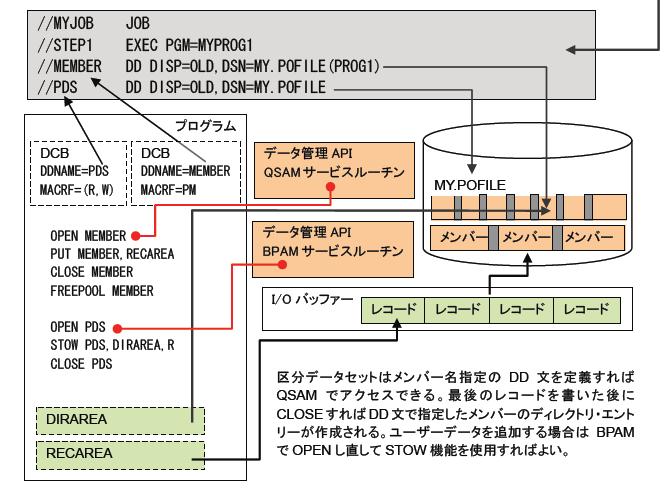
ディレクトリー部の構造
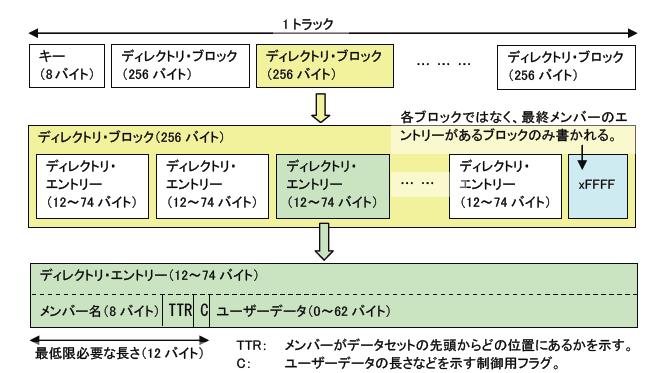
ディレクトリー・ブロックは、キー8バイト、データ256バイトの固定長非ブロック化レコードで構成されています。データセット自体のレコード形式やレコード長およびブロック長はメンバー部に対して使われ、ディレクトリー部はそれに関係なく常に同じフォーマットが使われます。また、各メンバーの情報を格納した領域をディレクトリー・エントリーと呼びます。ディレクトリー・エントリーは、12バイト~74バイトの可変長で、ブロック内に隙間無く詰められていてメンバー名順に並びます。ただし、1つのエントリーが複数のブロックにまたがることはありません。ブロックのキーには、そのブロック内の最終メンバーの名前が格納されており、ディレクトリー・エントリーの探索に使用されます。最終のメンバーのエントリーの次には、8バイトのxFF値が設定され、さらにそのブロックのキーにも設定されます。これによって最終メンバーのディレクトリー・ブロックを判別します。
ディレクトリー・エントリーは、メンバー名(8バイト)+メンバーの位置(3バイト)+データ部の長さ(1バイト)+可変長のユーザー・データで構成されています。ユーザー・データがなければ、エントリーは最小の12バイトです。ユーザー・データは、メンバーを登録したプログラムが任意に使用することができます。MVSが提供するユーティリティ・プログラムでも使われ、ISPFエディターはメンバーを作成・更新した日時やユーザー名、リンケージ・エディターはロードモジュールの属性やサイズなどローディングに必要な情報を格納します。
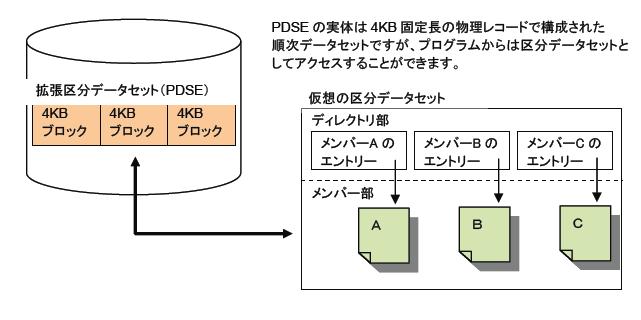
MVS限定ですが、「PDSE」と呼ばれる拡張区分データセットもあります。PDSEは従来のPDSの欠点が改良された新しいタイプの区分データセットで、DFSMSの機能によって提供されます。今までのPDSアクセス方式で利用できるためプログラム互換を持ちます。PDSEには、以下の利点があります。
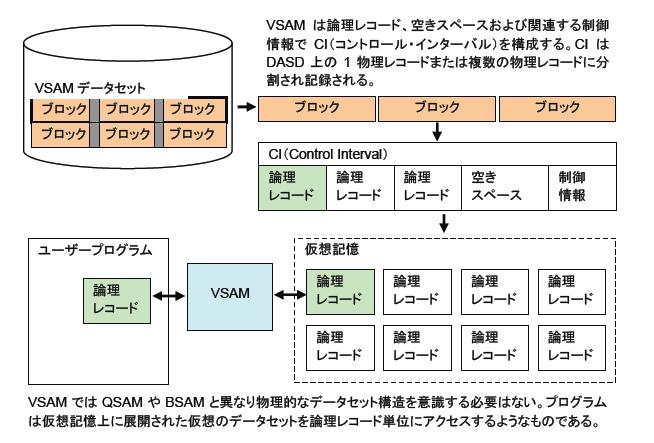
VSAMデータセット
VSAM(Virtual Storage Access Method)も、データをレコード単位に転送し管理するための仕組みですが、他のデータセットと異なり、OS/360からの互換ではなくS/370による仮想記憶の出現によって実装されたものです。当初からDASDと仮想記憶の使用を前提に設計されたもので、従来からあるデータセット編成とアクセス方式に比べ、以下のような特徴を持ちます。
VSAMでもデータの実体は、DASD上のデータセットとして格納されます。しかし、順次データセットや区分データセットのように、物理的な構造がそのままプログラムにマッピングされません。DASD上のデータセットには、VSAMによる内部フォーマットによってデータが整理されて格納されています。この中のデータを、プログラムで扱うレコードの形式に再構成して仮想記憶上に展開するのがアクセス方式としてのVSAMです。また、VSAMはカタログが前提のファイルシステムで、カタログ・データセット自身もVSAMによって構築されています。
VSAMは、以下の4種類のタイプのデータセットをサポートします。
KSDS(Key Sequenced Data Set)
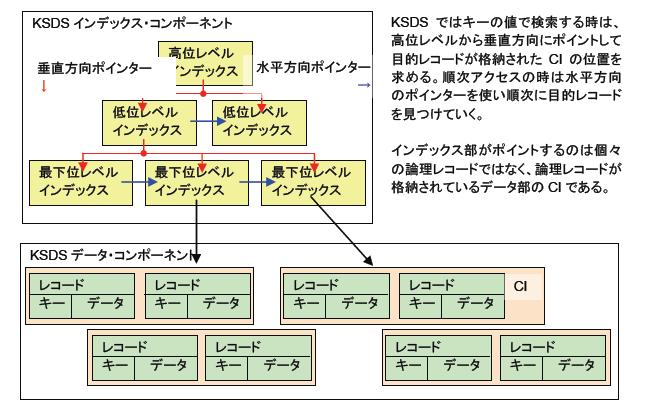
KSDSは、レコードの1部分がキーとして定義され、レコードがキーの値で順番に並んでいるVSAMデータセットです。KSDSデータセットは、キーを管理するインデックス部とレコードを格納するデータ部によって構成されます。レコードは、キーの順番で順次にアクセスすることもできますし、キーの値で直接アクセスすることもできます(実際に順番に並んでいるのはインデックス部で、データ部の並びは必ずしもキー順ではありません)。
KSDSは、データ管理が従来からサポートしていた索引順次データセット(ISAM)の代替としても使用できます。VSAMのKSDSは、データベースの原型とも言えるでしょう。
ESDS(Entry Sequenced Data Set)
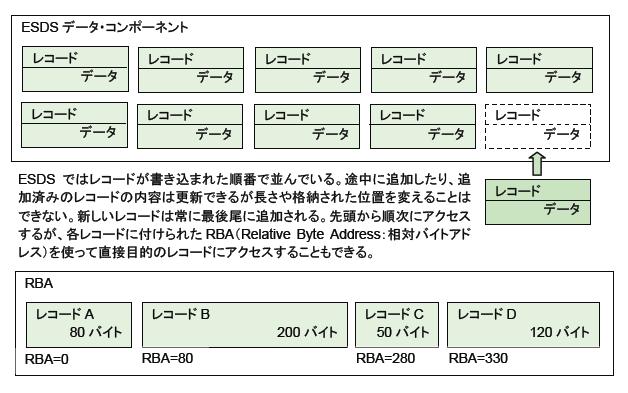
ESDSは、VSAMにおける順次データセットです。ESDSデータセットでは、レコードは入力順に並び、先頭から順次にあるいは先頭からの相対位置でアクセスすることができます。QSAMとBSAM双方の利点を併せ持つものと言えるでしょう。
RRDS(Relative Record Data Set)
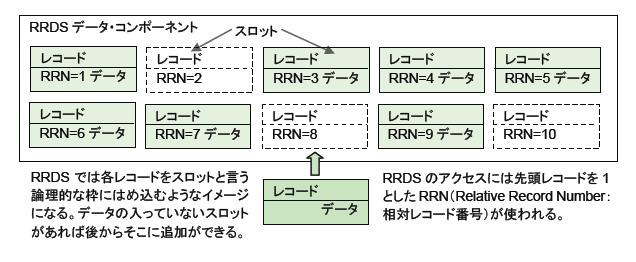
RRDSは、データセットをスロットと呼ばれる論理的な枠で区切り、レコードをその枠にはめ込むような形で格納するVSAMデータセットです。スロットには番号が付けられ、先頭から1、2、3…と順番に振られ、レコードは番号順に並びます。レコードは、番号で直接アクセスされます。
RRDSでもレコード番号を1つずつ増やしてアクセスすれば先頭から順番にアクセスすることもできますし、位置(番号)を指定すれば直接目的のレコードをアクセスすることもできます。ESDSデータセットと一見似ていますが、RRDSデータセット4ではスロットは順番に並びますが、レコードは必ずしもスロット順に入れる必要がありません。そのため、レコードを途中に追加したり(スロットが空いていれば)、削除したりすることもできます。RRDSデータセットは、ランダム・アクセスに向いている構造を持っており、データ管理が従来からサポートしていた直接データセット(DAM)の代替としても使用できます。
LDS(Liner Data Set)
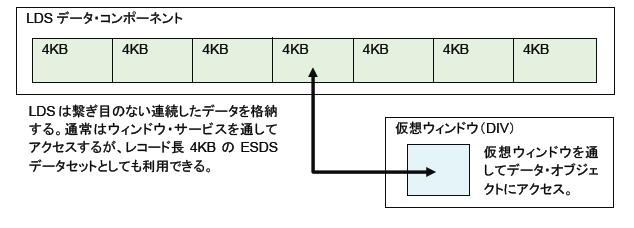
直訳されて線形データセットと呼ばれますが、KSDS、ESDS、RRDSの各データセットとは大きく異なり、論理的なレコードに分割されているわけではなく、先頭から最後まで、1つの繋がった連続したスペースによって構成されるVSAMデータセットです。VOS3ではFDS(Flat Data Set)と呼ばれています。レコードとしての論理単位はありませんが、データセットそのものは4KB毎に区切って記録されています。
LDSは、主に仮想記憶に入りきらない大量のデータを、メモリー上でアクセスできるようにする仕組みのために用いられます。この場合、LDS内のデータをデータ・オブジェクトと呼び、マッピングされたメモリー側を仮想ウィンドウと呼びます。この仕組みがDIV(Data-in-Virtual)で、PI(プログラミング・インターフェース)がウィンドウ・サービスです。DIVは、アセンブラー言語でなければ直接利用できない機能ですが、ウィンドウ・サービスAPIによってアセンブラー以外の言語からも利用することができます(MSPではDIVのアセンブラーマクロで、VOS3ではウィンドウ・サービス・ルーチンでAPIが提供されます)。また、LDSはマッピング・サービスによらず、VSAMで直接アクセスすることもできます。この場合は、レコード長4096バイトのESDSデータセットとしてアクセスします。
AMS(Access Method Service:アクセス方式サービスプログラム)
AMS(IDCAMS)は、主にVSAMデータセットを作成・維持・管理のために使われるユーティリティ・プログラムです。VOS3では、AMSとは呼ばれずVSAMユーティリティと呼ばれます。AMSの機能は広範囲かつ強力で、VSAM以外のデータセット(順次・区分データセットなど)に関しても取り扱うことができます。VSAMではデータセットをクラスターと呼び、AMSではVSAMデータセットを作成することを、クラスターを定義すると言います。むろんVSAMであっても、DASD上ではMVSの規定に沿ったデータセット名が付けられ、JCLのDD文にはそのデータセット名を指定します。
VSAMではさまざまな編成がサポートされ、キーによる検索やランダムなアクセスなどが論理レコード単位にできるため、アプリケーションによる業務用データの格納用に非常によく使われました。今日ではデータベース・システムの利用が一般化したため、アプリケーションにおけるメインのデータ・ストレージとしての利用度は減りましたが、現役のファイルシステムとして互換目的だけでなく多くの場面で利用されていますし、MVSのデータ・ストレージ機能の基盤として重要な役割を果たしています。