【2009/04/01 original author TAKAO】
すべてではありませんが、IBM系のソフトウェアはSMP/Eを使って導入するのが普通でしょう。これがまたわかりにくいソフトウェアなので習熟には時間がかかります。
それではどうしてメインフレームは導入にSMP/Eなんていうわけのわからんものを使っているのでしょうか?単純にコピーではいけないのでしょうか。理由は大別してふたつあります。
修正情報の履歴を明らかにすること
通常、モジュールをメンテナンスしていると複雑なモジュール関係が生じます。次の図で考え方を説明します。
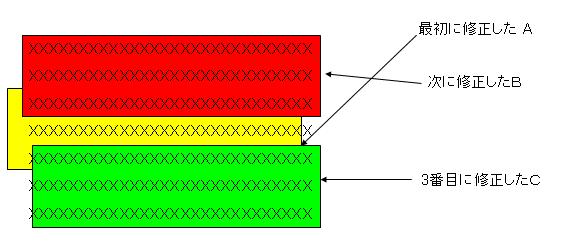
プログラムのソースコードを何度か修正したとします。最初の修正がA(黄色)だったとします。次にB(赤)は、黄色の修正を前提として行われています。次に三度目にC部分(緑)を修正しました。この場合、赤は関係しているかも知れないし、していないかもしれません。機械的には決められません。
つまり、
- 緑は黄色と赤を前提とした修正である
- 緑は黄色だけを前提とした修正である
どちらかが緑の修正情報の前提となります。このように、履歴がはっきりしていないと的確に修正情報を反映できません。Windowsなどではモジュールごと、ばさりと置き換えてしまうことが多いので、このような考慮は少ないかも知れません。このような管理をしている理由は、SMP/Eのもうひとつの目標に関係します。
修正情報をお客の環境にあわせて確実に適用する
モジュールをきちんとリンクエディット(連携編集、バインド)するのは、むつかしい作業です。モジュールの順序、与えるパラメータで再入可能とか、オーソライズドにするかなどが決まります。さらに、ユーザーが出口ルーチンなどを利用している場合もあります。そのため、モジュールを単純に新しいものと置き換えると、カスタマイズした機能が消失する可能性があります。この多くのカストマイズを許しているところが、メインフレームの特徴のひとつでもあります。それゆえ、修正情報を適用する場合には単純な置き換えでなく、システム部分のモジュールを置き換えて適切にリンクエディットしてロードモジュールを作り出します。
このふたつが大きな機能であるといえます。逆に、導入されていないプロダクトに関する修正情報を適用しようとしても、「ないよ」とはじかれることもSMP/Eの特徴です。
【2009/04/01 original author TAKAO】