【2010/09/01 original author KAMII】
データセットのI/O効率を上げる(続き)
VSAMデータセットのバッファリング方法を変更する(BLSR)
VSAMデータセットを拡張形式に変更してSMBを使用すれば、VSAMデータセットのアクセス・パフォーマンスはかなり向上します。特に、KSDSのランダム・アクセスにおいては顕著に向上します。しかしながら、いろいろな理由で既存のデータセットを変換するのはためらいがあるかも知れません。そのような場合は、SMBほどではないにしろ同様の効果を期待できる別の方法があります。順次アクセスであれば、BUFNDでバッファー数を増やすだけでもかなりの効果がありますので、ここではランダム・アクセスを前提に解説します。
Batch LSRを使う(z/OSのみ)
Batch LSR(以下BLSRと記す)は、VSAMのLSR(ローカル共用リソース)をプログラムによらずに行うMVSの機能です。BLSRを使うことで、COBOLなどでI/Oのコントロールを細かく行うことができない言語で作られたプログラムでも、アクセス頻度が高いINDEXコンポーネントをメモリー常駐させたり、DATAレコードに対する大容量のソフトウェア・キャッシュを用意したりすることができます。SMBを利用するにはVSAMデータセットをSMS管理データセットとして拡張フォーマットで作り直す必要がありますが、BLSRの場合はJCLのDDステートメントを変更するだけで済みます。
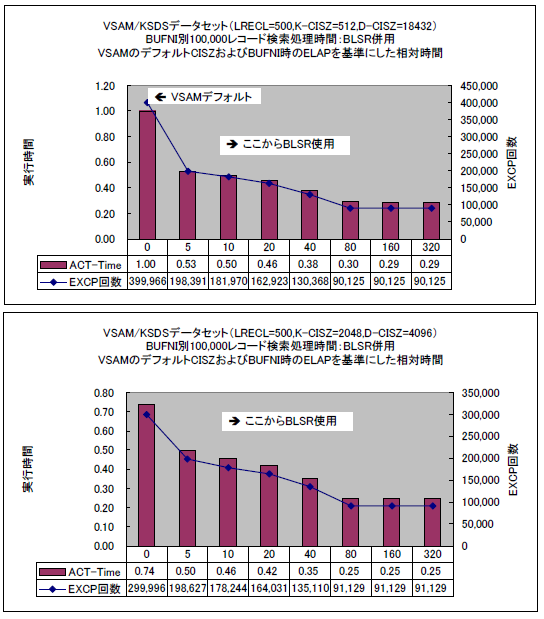
グラフは、従来からある基本フォーマットのVSAM/KSDSデータセットのランダム・アクセスにおける実行時間および発行されたI/O回数を示しています。上側はCIサイズをAMSデフォルトにしたもの、下側はINDEXは2KB、DATAは4KBのCIサイズにしたもので、INDEXコンポーネントのバッファー数を変更したものの実行結果です。バッファー数0はVSAMのデフォルト値を示します。バッファー数5はAMPパラメーターでBUFNI値を変更したもの、10以上はBLSRを併用したものです。AMPのBUFNIパラメーターだけでは10を超えたバッファー数を指定しても頭打ちでしたが、BLSRの場合はバッファー数80でガクンとI/O回数が減っています。これはバッファー数80になるとINDEXコンポーネントのレコードがすべてバッファーに展開されI/Oがでなくなったことを示します。
SMBほどではないものの、INDEXをメモリー常駐させるだけでも十分な効果があることがわかります。なお、このサンプルではBLSR使用時のメモリー増加量は約6MB(BUFNI=320)でした。
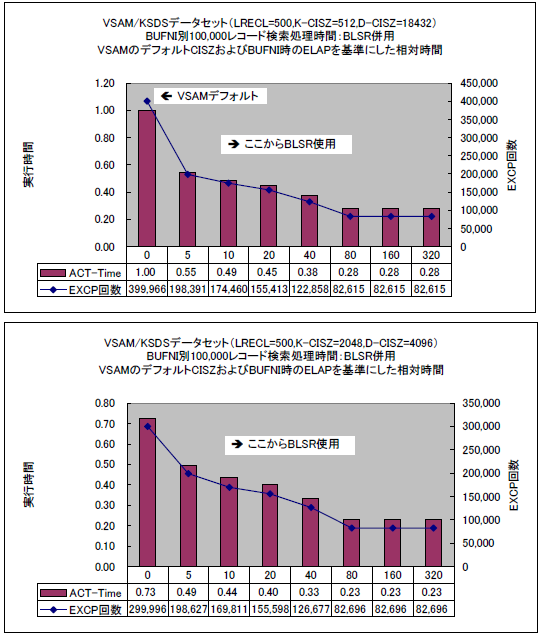
BLSRを使用する際、DATAバッファーの数も思い切って増やせばSMB並みに効果を上げることもできます。グラフの上側はCIサイズが18KBの時にDATAバッファーを500個、下側はCIサイズが4KBの時にDATAバッファーを2500個にしたものです。メモリー増加量もSMB並みの約10MB程度に増えますが、実行時間もI/O発行回数もSMB並みのパフォーマンスを出せます。
BLSRもJCLのDDステートメントの変更で簡単に利用できます。ただし、予めBLSRがMVSのIPLパラメーターでサブシステム登録されていなければそれを行わねばなりません(オペレーター・コマンドで動的に追加することもできます)。
|
1 2 3 4 5 6 7 8 |
■SYS1.PARMLIBのIEFSSNxxパラメーター: ********************************* Top of Data ********************************** SUBSYS SUBNAME(BLSR) /* BATCH LSR */ INITRTN(CSRBISUB) ******************************** Bottom of Data ******************************** ■オペレーター・コマンドで追加の場合: SETSSI ADD,SUBNAME=BLSR,INITRTN=CSRBISUB |
VSAMデータセットがDD名SYSUT1でDDステートメントに定義されている場合、BLSRを利用したアクセスを行うには次のようにJCLを変更します。
|
1 2 3 4 5 |
//SYSUT1 DD DISP=SHR,DSN=UAP5.GRK7200.MASTER ↓ ↓ //SYSUT1 DD SUBSYS=(BLSR,'DDNAME=LSRUT1,BUFNI=100,BUFND=500') //LSRUT1 DD DISP=SHR,DSN=UAP5.GRK7200.MASTER |
プログラムがアクセスするDD名のDDステートメントをBLSRの定義に変えます。元のDDステートメントはDD名を変更し、BLSRのSUBSYSパラメーターで変更後のDD名を指定します。プログラムとVSAMの間にBLSRを介在させるわけです。BUFNIやBUFNDはAMPパラメーターではなく、BLSRのSUBSYSパラメーターで指定します。BUFNIはINDEXコンポーネントのレコードがすべて入るぐらいの大きさが効果的です。INDEXコンポーネントがどのくらいのレコードを抱えているかはAMSのLISTCATを取ればわかります。ランダム・アクセスの場合、索引さえメモリー常駐させれば十分なので、DATAコンポーネントのCIをキャッシュするBUFNDは指定しなくてもいいと思いますが、メモリーをいっぱい使ってでもかまわないから減らせるI/Oは少しでも減らしたいのならば思い切った数を指定します。CIサイズ18KでBUFND=500、CIサイズ4KでBUFND=2500の時、メモリーは約4~5MB増えた記録が残っていました。
Batch LSRもMVS固有の機能なのでMSPとVOS3では使えません。なお、VOS3には似たような機能としてHAF(VSAM高速アクセス機能)というのがあります。ただし、展開先は空間固有のリージョンではなく、CSAもしくはデータ空間となっています。MSPにも同等の機能があるかも知れませんので必要ならMSPのマニュアルなどで探してみてください。
なお、昔はINDEXのアクセス速度を向上させるために、KSDSデータセットを作成する際にIMBEDあるいはREPLICATEというオプションがありました。IMBEDは索引コンポーネントの一部であるシーケンスセットという部分をDATAコンポーネントの中に書いてしまうもので、REPLICATEは1つのトラック内に同じ索引レコードをいくつも書いてしまうもので索引が10レコードあるとそれだけで10トラック使ってしまうものです。スペース量を犠牲にしてでもこんなことをしていたのは、ディスクの回転待ち時間やアクセスアームの移動時間を少しでも減らして索引のI/O効率を上げるためでした。トリッキーですがハードウェアの構造的な特性を利用した苦肉の策でもありました。しかし、現在のz/OSではもはやこのようなオプションはサポートされていません。大きな理由は、現在のハードディスクには十分な量のキャッシュメモリーが積まれているため、このような工夫をしてもパフォーマンス上のメリットがなくなったからです。そうなると余計なスペース量を使うなどのデメリットだけが残ってしまいオプション機能として残す意味はなくなります。MSPやVOS3ではまだ残っているオプション機能かも知れませんが、使うメリットはほとんどないかと思います。
以上、全9回にわたり「バッチ処理のパフォーマンスを改善する」ということでまとめてみました。チューニングに関してはいろいろな方法があるのですが、既存のリソースの中で行う、お金も掛けない、むずかしいチューニングの知識もいらない、運用への悪影響もほとんどない、大がかりな作業をせずに実現できる(PARMLIBを直すのもできれば避けたい)、という観点で紹介しました。
【2010/09/01 original author KAMII】