【2010/08/05 original author KAMII】
データセットのI/O効率を上げる(続き)
順次編成データセットのブロックI/Oバッファーを増やす
順次データセットのアクセスでは、バッファー数を増やすことで一度に複数個のブロックを読み書きすることができます。ブロックサイズの大きさは一度に何レコードをまとめて読み書きするかでしたが、バッファーの数は一度に何ブロックをまとめて読み書きするかということです。バッファー数を増やすことで複数のブロックを先読み(書き戻し)することでデバイスへのI/O回数を減らすことができます。
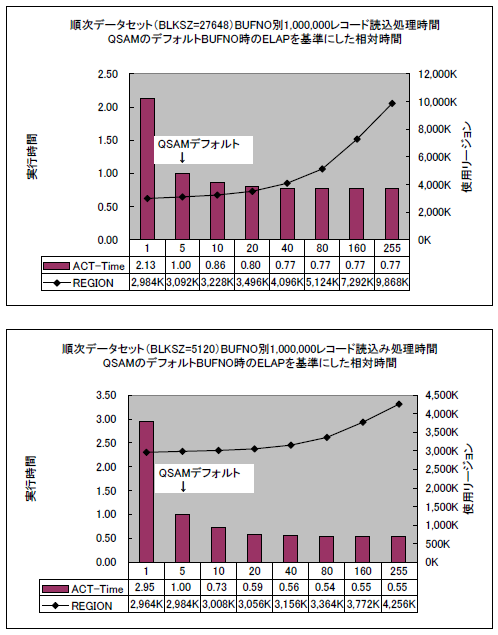
グラフはバッファー数と実行時間および消費されるメモリー量を示しています。読み込み処理の例ですが、書き込み処理であっても同様のカーブを描きます。バッファー数は1から255個の範囲で指定できますが、これも多くすればよい、というわけではなくある程度のところで効果は頭打ちになります。QSAMによる一般の順次データセット・アクセスでは、バッファー数のデフォルトは5個です。テープ上のLBIデータセットでは2個、PS/Eデータセットは2×トラックあたりのブロック数×ストライプ数で求めた個数(圧縮データセットの場合は1個)です。
大量のレコードが格納された順次データセットをアクセスするプログラムの場合、バッファー数を増やすことでデータセットのI/O処理の効率を上げることができます。ただし、増やしてもせいぜい10から20個程度。ブロックサイズが小さい場合で20から40個程度。過去に試した結果では、それ以上増やしてもメモリー使用量の増加に見合うだけの実行時間短縮は望めませんでした。また、SYSOUTデータセットへの書き込みに関しては、JES2が独自の処理を行っているのでアプリケーション側でのバッファー個数はスプール書き込みのパフォーマンスに影響しません。
デフォルトでもバッファリング制御がされているため、すでに適切なブロックサイズを持つデータセットであれば劇的に実行時間が減るわけではありませんが、小さなブロックサイズほどBUFNOの効果は顕著です。何らかの理由で小さいブロックサイズに固定してしまっているアプリケーション、ブロックサイズは小さいままだが昔から延々と使われていて今さら直せないアプリケーション、などでは少しの手間でそれなりの効果を期待できます。上のグラフ(右側)のLRECL=512でBLKSIZE=5120のケースでは、ELAP時間は約6割に減っています。これは1時間掛かるバッチが36分に短縮されることを意味します。実際にはさまざまなジョブが他にも実行されるため単純には行きませんが、デバイスへのI/O回数の削減はI/O時間だけでなく、I/Oの要求やI/Oの完了を処理するためのOS側のCPU使用量も減ることになるので、他のジョブも含めたシステム全体で見れば決して意味がないことではありません。
バッファー数の変更は、JCLのDDステートメントにDCBパラメーターを追加することで行うことができます。
|
1 2 |
//SYSUT2 DD DISP=SHR,DSN=dsname, // DCB=(BUFNO=20) |
バッファー数は、プログラムが使用するリージョン内のメモリー量に大きく影響を与えます。データセットのブロックサイズが大きいほど顕著です。消費されるリージョン内のメモリーはブロックサイズの倍数単位で増えることは知っておくべきです。特に、複数のデータセットを同時にアクセスするプログラムが、アクセスする全ての順次データセットのバッファー数を変えれば増える量はさらに増加します。しかし、適切なバッファー数は増えたメモリー量に見合うだけの効果があります。
なお、I/Oバッファーはz/OSのCOBOLプログラムなら16MBラインより上の拡張リージョンに作られるので通常はREGIONパラメーターの値を気にする必要はありません。ただし、古くから使われているアセンブラーのプログラムで31ビットモードDFPに対応していなかったり、MSPの場合はSAMのI/Oバッファーは16MBラインより下の基本リージョンに作られますから、REGIONサイズの調整は必要になります。
【2010/08/05 original author KAMII】