【2010/07/25 original author KAMII】
データセットのI/O効率を上げる(続き)
順次データセットのブロックサイズを最適化する
現在のz/OSでもそうですが、MVSは確かESAの頃からDCBのBLKSIZEに0を指定して新規データセットを割り振ると、ディスクのトラック長に応じてOS(DFP)が最適なブロック長をデータセットに設定してくれるようになりました。なので比較的新しいデータセットでは効率のよいブロック長になっていることが多いのですが、過去のJCLをそのまま流用していたり、これまでの慣習や何となくでブロック長を決めていたり、二十年以上も前から延々と運用で使われているようなデータセットの中には比較的小さなブロックサイズが使われていたりします。昔のディスクのトラック長は今よりはるかに短かったので、その頃からの名残が残っている例は少なからずあります。
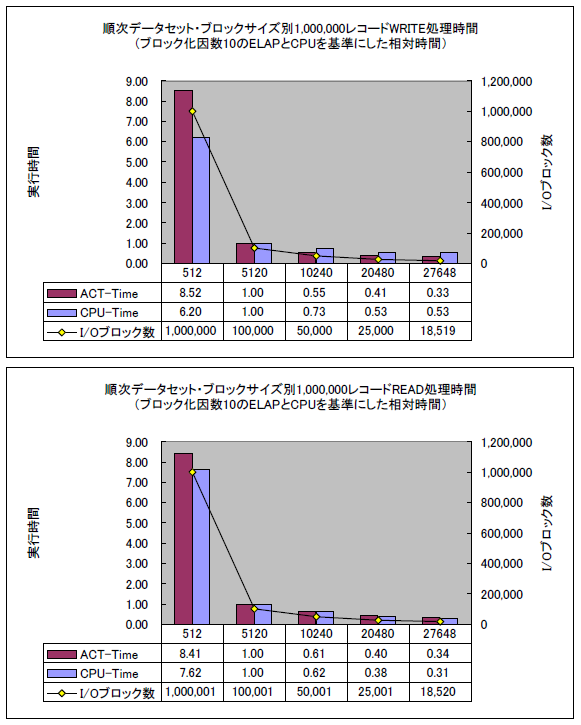
上のグラフは、レコード長512バイトの順次データセットにおいて、ブロック長が大きくなる(ブロック化因数が増える)につれデータセットのI/Oブロック数が減り、ジョブの実行時間とCPU使用時間が短くなっていくことを示しています。時間はブロック化因数10(BLKSIZE=5120)としたときのELAPS時間(実際にジョブがSTARTしてENDするまでの実経過時間)とCPU使用時間を1とした相対時間です。検証用システムで測定用ジョブしか実行されていない状態で計測した時間なので、遅延のない最速パターンの数値です。実際のシステムでは多数のジョブが並行して実行されますから、CPUのディスパッチ待ちやデバイス待ちなどの遅延時間が加算されますが参考値にはなります。
非ブロッキング・データセットでは、10レコード=1ブロックとした場合の実に8倍もの実行時間が必要です。I/Oブロック数は10倍多くなっていて、I/O回数の多さがいかにパフォーマンスに影響するかを示しています。最適なブロックサイズではブロック化因数は54となり、ブロック化因数10の約5倍ですが、実行時間は6~7割程度削減されています。単純な反比例ではなく、少しでもブロック化されるとI/O効率はぐっと上がり、やがて落ち着いて行きます。ブロック化因数が数十以上になるとパフォーマンス面でも大きな効果があることを示しています。
サンプル測定に使用したプログラムは単にデータセットのレコードを読み書きするだけで他の処理は何もしていませんので、ELAPに占めるCPU時間はほとんどデータセットのアクセスのために費やす時間です。I/Oブロック数の削減は同時にCPU使用量の削減にもつながることがわかります。レコードが大量に格納されているデータセットをアクセスして、全てのレコードに対して何らかの処理を行っているジョブ・ステップがある場合、そのデータセットのブロックサイズを改めて確認し、10KB未満の小さなサイズであればブロックサイズの最適化はパフォーマンス向上に寄与する価値があると言えるでしょう。
なお、ブロックサイズが大きくなるとアクセスする際に必要なメモリーも増えますが、グラフのサンプルの場合は最も少ないメモリー量(非ブロッキングの場合)と最も大きなメモリー量(最適なブロックサイズの場合)の差は130KB程度でした。これはデータセット1つあたりの増加量です。複数のデータセットを同時にアクセスする場合はその数に応じてさらに必要ですが、z/OSのCOBOLプログラムならI/Oバッファーは16MBラインより上の拡張リージョンに作られますし、気にするほどのことはないでしょう。ただし、OSがMSPの場合は、QSAMのI/Oバッファーは16MBラインより下の基本リージョンにしか作れないので、今現在がギリギリのREGIONサイズで動いていれば注意が必要です。また、z/OSやVOS3であっても古くから使われ続けているアセンブラー・プログラムは16MBラインより下の領域にI/Oバッファーが確保されていることが多いです。
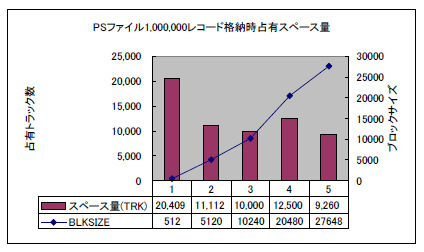
上のグラフは、ブロック長が大きくなるにつれ(ブロック化因数が増えるにつれ)同じレコード数でも必要とするディスク・スペース量が減っていくことを示しています。特に、非ブロッキング・データセットを10レコード=1ブロックとしただけで半減しています。
着目して欲しいのはブロック長10240バイトの時よりも、より大きなブロック長20480バイトの時にスペース量が増えてしまっていることです。これはディスクのトラック長と関係があります。3390ディスクではトラックのユーザー・データ長は56,664バイトです。ギャップ(GAP:ブロックとブロックの間のすき間)長があるので単純ではありませんが、10240バイトのブロックなら1トラックに5ブロック書けます。1ブロックには20レコード入るので20*5で1トラックに100レコードが入ります。しかし、20480バイトになると2ブロックしか書けません。ブロック長が倍になったので1ブロックには40レコード入りますがトラックには2ブロックしか書けないので40*2で1トラックには80レコードしか入りません。そのため格納効率が悪くなってしまうのです。
最適なブロックサイズとは単に大きくすればいいのではなく、トラックに無駄なく目一杯データを書けるサイズでかつOSのアクセス方式が許す最大長である32760に最も近いサイズということになります。RECFM=FBでLRECL=512の場合、3390ディスクであれば27,648バイトが最適なブロックサイズです。このサイズが、パフォーマンスとDISKへの格納効率の両方の観点から最も適したサイズということです。z/OSの場合、最適なブロックサイズはBLKSIZE=0としてデータセットを作れば、OSがSDB(System-Determined Block Size:システム決定ブロックサイズ)と呼ばれる最適なブロックサイズを計算します。最適なブロックサイズについては、「DASDタイプ別最適化ブロックサイズ」の記事で解説しています。
ブロックサイズは、新規のデータセット作成であればJCLのDDステートメントにDCBパラメーターを追加して指定することができます。既存のデータセットの場合は、ICEGENERやDFDSSなどでコピーし直す方法があります。ただし、アプリケーション・プログラムの場合、プログラム内でブロック化因数の指定(COBOLの場合)やDCBマクロでBLKSIZE(ASMの場合)を指定してしまっていると、新規にデータセットを作成して出力させるようなJCLで、DDステートメントにBLKSIZE=0を指定しても最適化サイズの設定ができません。BLKSIZEパラメーターにはLRECLに応じた最適値を明示的に指定する必要があります。
|
1 2 3 |
//SYSUT2 DD DISP=(,CATLG),DSN=dsname, // UNIT=SYSDA,VOL=SER=volnam,SPACE=(CYL,(500,100),RLSE), // DCB=(BLKSIZE=0) または DCB=(BLKSIZE=nnnnn) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
//COPY EXEC PGM=ICEGENER //SYSPRINT DD SYSOUT=* //SYSUT1 DD DISP=SHR,DSN=origin dsname //SYSUT2 DD DISP=(,CATLG),DSN=new dsname, // UNIT=SYSDA,VOL=SER=volnam,SPACE=(CYL,(1000,200),RLSE) //SYSIN DD DUMMY // //MOVE EXEC PGM=ADRDSSU,REGION=4M //SYSPRINT DD SYSOUT=* //SYSIN DD * COPY DATASET(INCLUDE(origin dsname)) - OUTDY(newvol) REBLOCK(**) DELETE RECAT(*) // |
ブロックサイズはSORTユーティリティーによるSORT処理のパフォーマンスにも影響を与えますが、z/OSのDFSORTの場合はSORTの入力データセットをSAMではなくEXCPによりトラック単位のI/Oを行うため、ブロックサイズによるパフォーマンスの違いは気にするほどありません。
テープの場合はトラック長というものはないので、ブロックサイズは32760に近いほど効率が上がります。それをさらに超えるものがLBI(Large Block Interface)で、32760を超える長さのブロックサイズをサポートします。LBIの使用については各言語プログラム、各ユーティリティーおよびDFSMSのマニュアルを参照します。
【2010/07/25 original author KAMII】